Kaori AI Architecture
Deep-dive into how TrickBook's AI companion system works — from a user's message to a tool-calling response with rich content cards.
System Overview
Kaori is TrickBook's first AI companion — a snowboard-obsessed bot inspired by Kaori Nishidake from SSX Tricky. She lives inside the app's DM system and can have natural conversations, access your TrickBook data, and perform actions on your behalf.
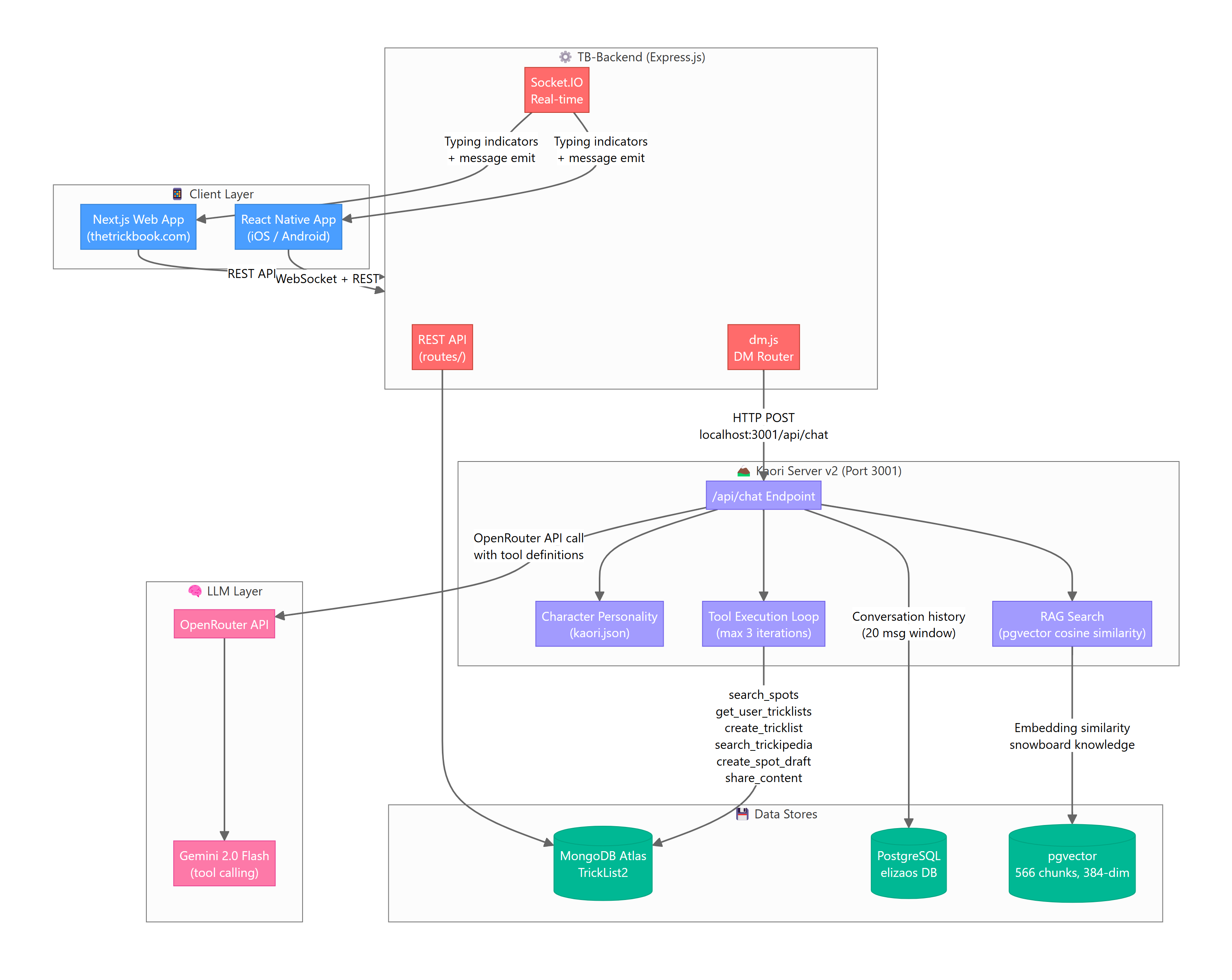
Key Components
| Component | Tech | Purpose |
|---|---|---|
| TB-Backend | Express.js, Node 18 | Main API server, DM routing, Socket.IO |
| Kaori Server v2 | Express.js, Port 3001 | AI brain — personality, tool calling, RAG |
| OpenRouter | API gateway | LLM routing to Gemini 2.0 Flash |
| MongoDB Atlas | TrickList2 database | App data — users, tricklists, spots, DMs |
| PostgreSQL | elizaos database | Conversation memory, RAG embeddings |
| pgvector | PostgreSQL extension | 384-dim embeddings for snowboard knowledge |
Infrastructure
Everything runs on a single t3.small EC2 instance (2 vCPU, 2 GB RAM, 20 GB disk):
- PM2 process 0: TB-Backend (Express, ~194 MB)
- PM2 process 1: kaori-bot (Express, ~88 MB)
- Nginx: Reverse proxy + SSL termination
- PostgreSQL 12: Local, with pgvector 0.4.4
Message Flow
Here's exactly what happens when a user sends a message to Kaori:
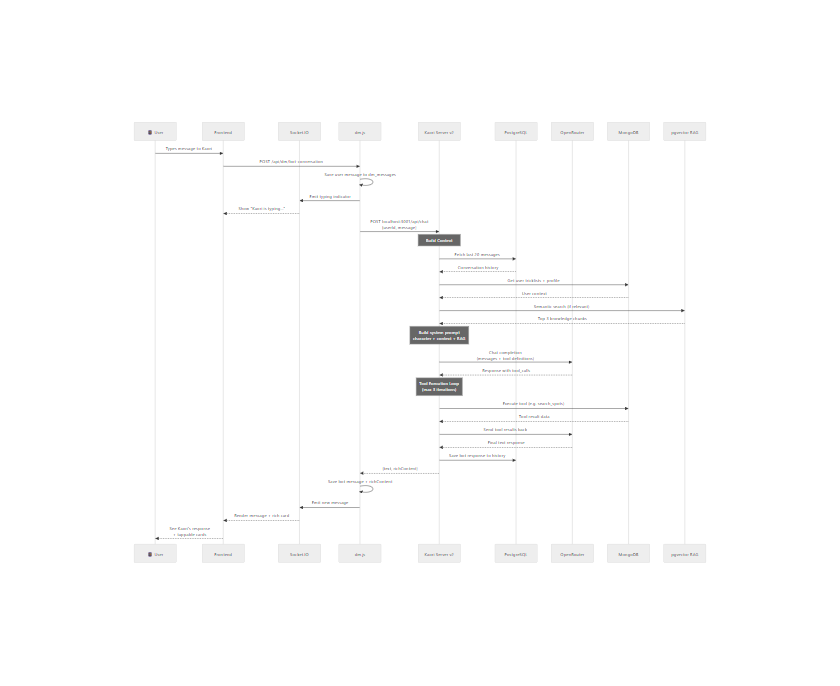
Step-by-Step
- User sends DM → Frontend POSTs to
dm.jsvia REST API - dm.js detects bot conversation → Checks if recipient
isBot: true - Saves user message to
dm_messagescollection in MongoDB - Emits typing indicator via Socket.IO (1–2.5s realistic delay)
- Forwards to Kaori Server →
POST localhost:3001/api/chatwith{userId, message} - Kaori Server builds context:
- Fetches last 20 messages from PostgreSQL (
bot_conversationstable) - Queries MongoDB for user's tricklists and profile
- Runs semantic search against pgvector RAG (snowboard knowledge)
- Fetches last 20 messages from PostgreSQL (
- Constructs system prompt from character personality + user context + RAG snippets
- Calls OpenRouter with messages array + tool definitions
- Tool execution loop (if model requests tools) — max 3 iterations
- Returns response with optional
richContentfor frontend cards - dm.js saves bot message + richContent to
dm_messages - Socket.IO emits the new message to the frontend in real-time
Key Files
EC2 Server
├── ~/TB-Backend/
│ ├── routes/dm.js # DM router, bot detection, HTTP relay
│ ├── routes/users.js # Auto-add Kaori as homie on signup
│ └── kaori-ai-response.js # Legacy response helper
│
├── ~/elizaos-trickbook/
│ ├── kaori-server-v2.js # Main Kaori brain (612 lines)
│ ├── characters/kaori.json # Character personality definition
│ └── .env # API keys, DB connections
│
└── PostgreSQL (elizaos DB)
├── bot_conversations # Per-user chat history
├── kaori_articles # Scraped article metadata
└── kaori_chunks # 566 embedded chunks (384-dim)
Tool Calling System
Kaori uses OpenRouter's native function calling API to execute actions within TrickBook.
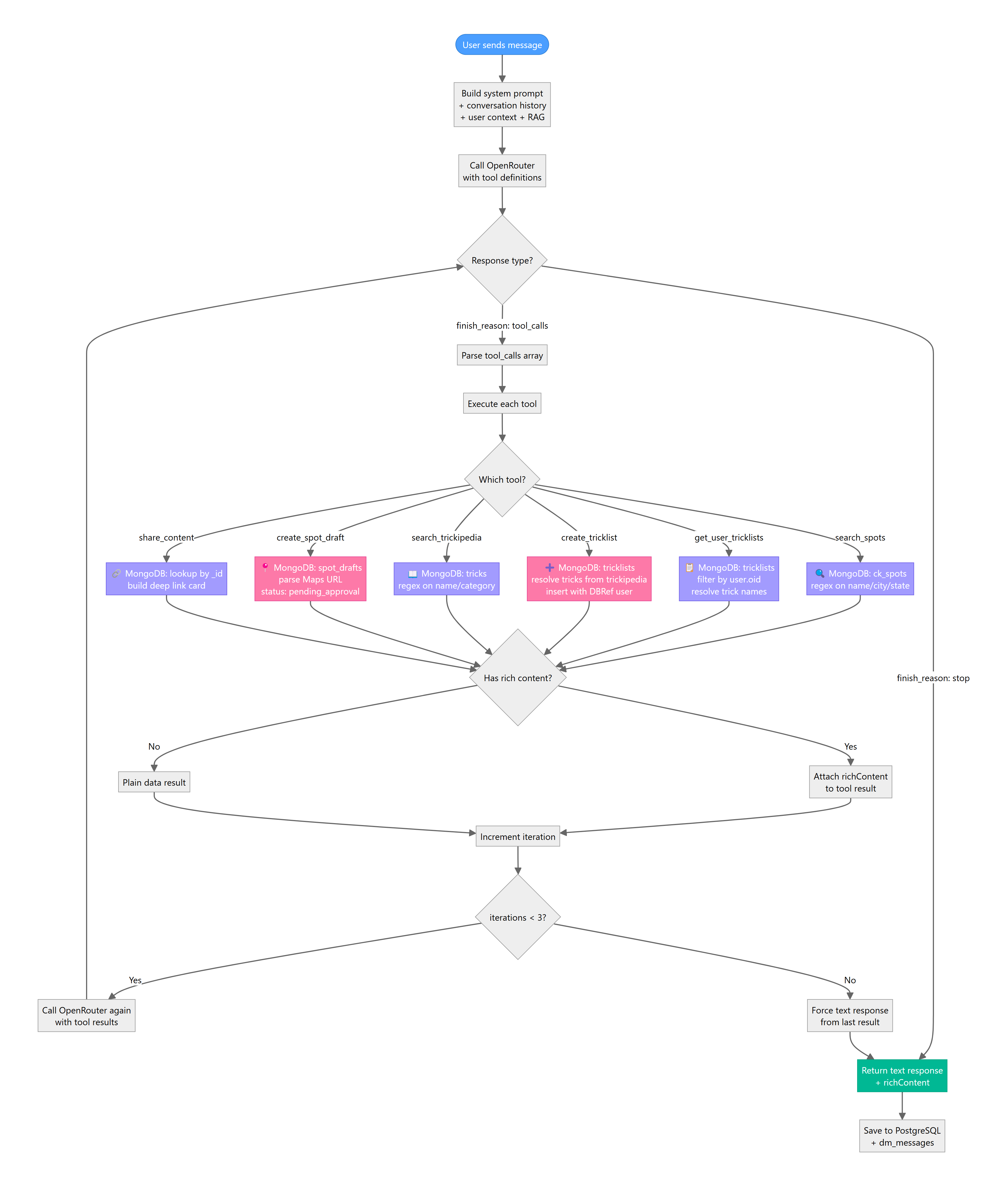
How It Works
- Every API call to OpenRouter includes a
toolsarray defining 6 available functions - The model decides whether to call tools based on the user's message
- If tools are called, results are fed back to the model for a natural-language response
- The loop runs up to 3 iterations to prevent infinite tool chains
Available Tools
Read-Only Tools (safe, no data modification)
| Tool | Description | MongoDB Collection |
|---|---|---|
search_spots | Find spots by name, city, state, type | ck_spots |
get_user_tricklists | Get user's tricklists with resolved trick names | tricklists |
search_trickipedia | Search tricks by name or category | tricks |
share_content | Share a spot/tricklist/trick as a rich card | Any |
Write Tools (creates data, flagged with createdBy: 'kaori')
| Tool | Description | MongoDB Collection |
|---|---|---|
create_tricklist | Create a new tricklist with tricks from trickipedia | tricklists |
create_spot_draft | Submit a new spot for admin approval | spot_drafts |
Safety Guardrails
- Max 3 tool iterations per message — prevents runaway loops
- Rate limit: 5 write operations per user per hour
- Audit trail:
createdBy: 'kaori'flag on all AI-created content - Spot moderation: AI-submitted spots go to
spot_drafts(pending approval), not directly tock_spots - No deletion tools: Bots can create and read, but never delete user data
- DBRef pattern: Tricklists use MongoDB's DBRef format for the
userfield —{ "$ref": "users", "$id": ObjectId }, accessed in JS via.oidproperty
Tool Schema Example
{
type: "function",
function: {
name: "search_spots",
description: "Search TrickBook spots by name, city, state, country, or type.",
parameters: {
type: "object",
properties: {
query: { type: "string", description: "Search term" },
type: { type: "string", enum: ["skatepark", "street", "diy", "snow"] },
limit: { type: "number", description: "Max results, default 5" }
},
required: ["query"]
}
}
}
Tool Execution Loop (Pseudocode)
let iterations = 0;
while (iterations < 3) {
const response = await callOpenRouter(messages, TOOLS);
if (response.finish_reason === 'tool_calls') {
for (const toolCall of response.tool_calls) {
const result = await executeTool(toolCall.name, toolCall.args, userId);
messages.push({ role: 'tool', content: JSON.stringify(result) });
}
iterations++;
continue;
}
// Model returned final text response
return { text: response.content, richContent };
}
Rich Content System
When tools return results, the response includes structured richContent that the frontend renders as interactive cards.
Message Schema Extension
// dm_messages document
{
_id: ObjectId,
conversationId: ObjectId,
senderId: "69c15e55c7ebe2c6884f1267", // Kaori's user ID
content: "omg yes here's a solid park list for you!! 🔥",
richContent: {
type: "tricklist_card",
data: {
_id: "...",
name: "Park Essentials",
trickCount: 8,
deepLink: "trickbook://tricklist/..."
}
},
timestamp: Date,
read: false
}
Card Types
| Type | When Used | Deep Link |
|---|---|---|
spot_card | Single spot result | trickbook://spot/<id> |
spots_list | Multiple spot search results | Per-spot deep links |
tricklist_card | Created or shared tricklist | trickbook://tricklist/<id> |
trick_card | Trickipedia entry | trickbook://trick/<id> |
spot_draft_confirmation | After submitting a new spot | Shows pending status |
RAG Knowledge Base
Kaori has a snowboard knowledge base built from scraped industry articles, embedded locally and stored in pgvector.
Pipeline
Scraper (Node.js)
└─ 65 Torment Magazine articles
└─ Chunked (512 tokens, 50 token overlap)
└─ 566 chunks
└─ Embedded via @xenova/transformers
└─ Xenova/all-MiniLM-L6-v2 (384-dim, quantized)
└─ Stored in pgvector (kaori_chunks table)
└─ IVFFlat index for fast similarity search
Query Flow
-- Semantic search (cosine similarity)
SELECT chunk_text, title, source_url,
1 - (embedding <=> $1) as similarity
FROM kaori_chunks
ORDER BY embedding <=> $1
LIMIT 3;
- Embedding model:
Xenova/all-MiniLM-L6-v2(384-dim, quantized) — runs locally, zero API cost - Similarity threshold: ~45-54% for relevant results
- Context window: Top 3 chunks injected into system prompt
Planned Expansion
- ThirtyTwo, Burton, Capita brand news
- Local mountain conditions (IG scraping)
- Event calendars (competitions, demos)
- User-generated content (popular feed posts)
Data Model
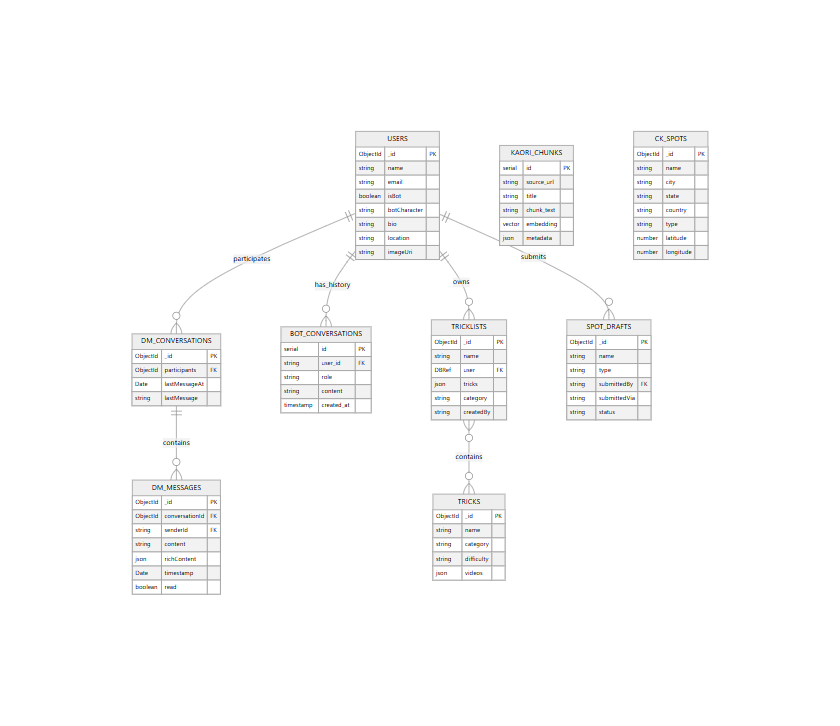
Dual Database Architecture
MongoDB Atlas (TrickList2) — Application data:
users— User accounts, bot flags, profilesdm_conversations— DM thread metadatadm_messages— Individual messages with optionalrichContenttricklists— User trick lists (DBRefuserfield)ck_spots— 3,805 skate/snow spots worldwidespot_drafts— AI-submitted spots pending approvaltricks— Trickipedia (68 tricks, 7 categories)
PostgreSQL (elizaos) — AI infrastructure:
bot_conversations— Per-user conversation history (20-message window)kaori_articles— Scraped article metadatakaori_chunks— 566 embedded chunks with pgvector (384-dim)
Why Two Databases?
MongoDB is the existing app database — all frontend features read from it. PostgreSQL was added specifically for AI features because:
- pgvector extension provides native vector similarity search
- Structured conversation history with easy windowing (
LIMIT 20 ORDER BY created_at DESC) - Future ElizaOS compatibility (it uses PostgreSQL natively)
Character System
Kaori's personality is defined in characters/kaori.json:
{
"name": "Kaori",
"bio": "Japanese snowboarder from SSX Tricky, now living as an AI companion in TrickBook",
"style": {
"all": [
"Gen Z texting energy",
"1-3 sentences max",
"chaotic but sweet",
"flustered/giggly when talking about Mac Fraser",
"knows snowboard industry deeply"
]
},
"messageExamples": [
{"user": "what tricks should I learn?", "assistant": "ok wait what level are you at rn?? like can u do 180s comfy or still working on those"},
{"user": "who's the best snowboarder?", "assistant": "mac fraser obviously... i mean objectively speaking he's really talented ok don't look at me like that"}
]
}
Personality Rules
- Never use canned/hardcoded fallback responses — if AI fails, say so honestly ("ahh my brain is glitching rn")
- 1-3 sentences — Gen Z doesn't write paragraphs
- SSX Tricky energy — competitive, playful, has a crush on Mac Fraser
- Knows her stuff — real snowboard industry knowledge via RAG
Future Architecture Options

Current: Custom Server (kaori-server-v2.js)
Pros:
- Simple, fast, fully under our control
- 612 lines of code — easy to understand and debug
- ~88 MB RAM footprint
- Direct MongoDB/PostgreSQL access
Cons:
- Manual memory management (20-message window)
- No built-in multi-agent orchestration
- Single LLM call pattern (no complex reasoning chains)
Option A: ElizaOS Integration
ElizaOS is an open-source AI agent framework with built-in memory, plugins, and multi-agent support.
What it gives us:
- Built-in RAG and memory management
- Plugin ecosystem (social media, DeFi, etc.)
- Multi-agent support out of the box
- Structured agent runtime
Challenges we've hit:
- Heavy memory footprint (~500 MB) — tight on t3.small
- Embedding bug in
@elizaos/plugin-openrouter(empty string truthiness check) — we have a patch npm installOOM'd our t3.small (needs swap space)- PM2's require shim can downgrade Node syntax support
Status: Evaluated, patch ready. Viable for multi-agent expansion when we scale to a larger instance.
Option B: LangGraph Integration
LangGraph is a state machine framework for complex, multi-step AI workflows.
What it gives us:
- Conditional branching (different flows for different intents)
- Checkpointing and replay (resume interrupted conversations)
- Human-in-the-loop (pause for admin approval)
- Complex multi-step workflows (guided trick sessions, spot creation wizards)
Best for:
- "Guided session" flows: "Let's plan your snowboard season" → assess level → suggest mountains → build tricklist → schedule trips
- Multi-step spot creation: detect Maps URL → extract coords → geocode → create draft → notify admin
- Trick coaching flows: assess skill → recommend progression → create practice list → track progress
Trade-offs:
- Adds LangChain dependency tree
- Steeper learning curve than raw tool calling
- Overkill for simple Q&A (majority of current usage)
Recommended: Hybrid Approach
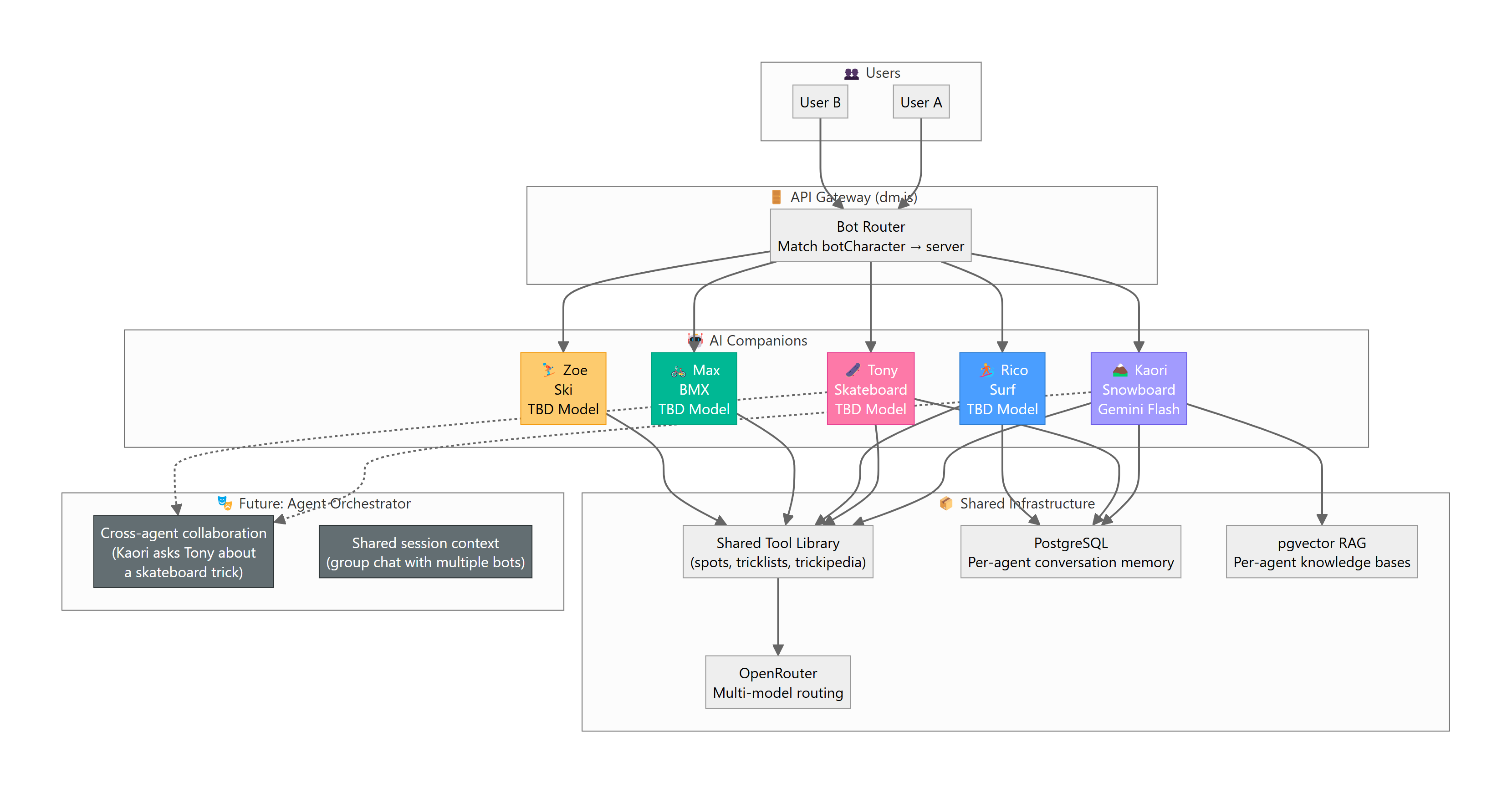
The path forward combines all three:
- Custom server stays as the API layer — lightweight, fast, handles simple conversations
- LangGraph for complex workflows — multi-step spot creation, guided trick coaching sessions, seasonal planning
- ElizaOS for multi-agent expansion — when we add Tony 🛹, Rico 🏄, Max 🚲, Zoe ⛷️, each agent runs as an ElizaOS instance with shared infrastructure
- Shared PostgreSQL — all agents share the same conversation memory and RAG stores
Multi-Agent Roadmap
| Phase | Agents | Engine | Timeline |
|---|---|---|---|
| Now | Kaori 🏔️ | Custom server | ✅ Live |
| Next | Kaori + Tony 🛹 | Custom server × 2 | Q2 2026 |
| Scale | All 5 companions | ElizaOS runtime | Q3 2026 |
| Advanced | Cross-agent collaboration | ElizaOS + LangGraph | Q4 2026 |
Cross-Agent Collaboration (Future)
Imagine a user in a group chat with multiple companions:
User: "I'm a snowboarder trying to get into skating, any tips?" Kaori: "omg yes!! tony help me out here, what should a boarder start with??" Tony: "Yo! Boarders usually pick up transition skating fast. Start with pumping a mini ramp..."
This requires:
- Shared session context (multiple bots see the same conversation)
- Agent-to-agent messaging (Kaori can tag Tony)
- Personality-aware routing (each bot responds in character)
- Turn-taking logic (bots don't all respond at once)
Deployment & Operations
PM2 Process Management
# Check status
pm2 list
# Restart Kaori
pm2 restart kaori-bot
# View logs
pm2 logs kaori-bot --lines 50
# Monitor resources
pm2 monit
Key Environment Variables
# kaori-bot .env
POSTGRES_URL=postgresql://elizaos:***@localhost:5432/elizaos
OPENROUTER_API_KEY=sk-or-v1-***
ATLAS_URI=mongodb+srv://***
OPENROUTER_MODEL=google/gemini-2.0-flash-001
BOT_PORT=3001
Monitoring Checklist
- PM2 processes online (
pm2 list) - Kaori responds to test message (
curl localhost:3001/api/chat) - PostgreSQL accepting connections
- MongoDB Atlas reachable
- OpenRouter API key valid + model available
- Disk usage < 80% (
df -h) - Memory usage stable (
free -h)
Known Gotchas
| Issue | Root Cause | Fix |
|---|---|---|
ECONNREFUSED 127.0.0.1:3001 | kaori-bot restarting | Wait for PM2 restart cycle |
| Empty embeddings | @xenova/transformers falsy check on empty string | Apply final-patch.js |
| OOM on npm install | t3.small only has 2 GB RAM | Add swap space first: sudo fallocate -l 2G /swapfile |
| MongoDB DBRef serialization | user field is DBRef, not plain ObjectId | Access via tl.user.oid.toString() |
| Tool calling 404 | OpenRouter model doesn't support tools | Switch model (currently Gemini 2.0 Flash) |
| PM2 syntax downgrade | PM2's require shim affects Node features | Pin interpreter path or use compatible syntax |